CloudBender™
CloudBender™ lets you connect your on-prem and cloud GPUs to the trainML platform and seamlessly run jobs on any CloudBender enabled system. When you start a notebook or submit a job, CloudBender will automatically select the lowest cost available resource that meets your hardware, cost, data, and security specifications.
The Future of Machine Learning Infrastructure
Machine learning infrastructure is difficult to get right for growing ML teams. Cloud infrastructure makes it easy to experiment without a large upfront investment, but gets really expensive once your usage accelerates. By the time you have enough activity to justify building your own deployment, you've built all your code and pipeline's on the cloud vendor's proprietary APIs. Even when you have significant credits available in a competitive cloud, the learning curve and migration costs of moving to multi-cloud might be prohibitive.
On-premise infrastructure has the best long-term cost profile, but makes it challenging to get started. Not only is there substantial up-front capital investment, but the IT expertise and overhead associated with installing, patching, securing, and monitoring servers might not be something your team is good at (or wants to be). Unlike Cloud, once you get the system up and running, you are constrained by the number of GPUs you own. If you have a 4-GPU server, what happens when you need a 5th?
Own the Base, Rent the Burst
trainML's CloudBender gives you the best of both worlds. It enables you to seamlessly run workloads across any infrastructure, anywhere. As you can see from the below graph, purchasing a GPU server and running your own workloads can lead to significant savings in the long run, even compared to reserved instances/committed use discounts.
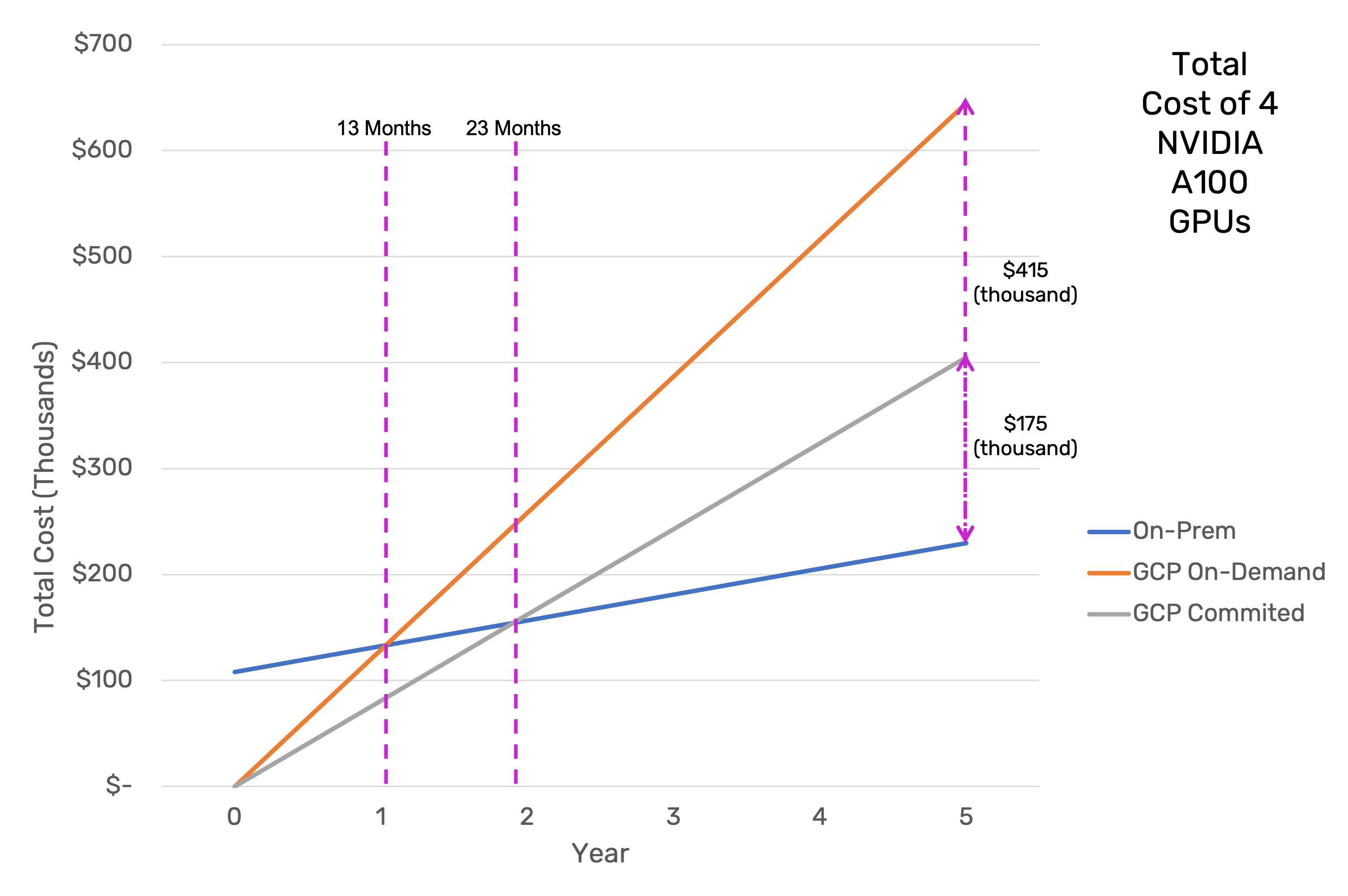
Compared to on-demand instances, the server pays for itself in less than 13 months, and 23 months compared to committed use instances. However, you might not have $100k+ to devote to a server yet, and might even have substantial credits from one of the major cloud providers that you can't ignore. CloudBender eliminates the incongruence between these considerations.
Seamless Experience
If you have credits from a cloud provider, you want to use those first. You can use CloudBender to configure a deployment inside your own cloud provider account, so that all the resource costs are being deducted from your credit balance. (Be sure to contact us to find out how to waive the usage fee for your cloud provider as long as you have credits remaining.) Now, instead of building pipelines and automation scripts that lock you into that cloud provider, you can instead use the trainML SDK/CLI to send jobs through the trainML interface. CloudBender will route all your trainML activity to the resources inside your cloud account.
Eventually, you will exhaust your credits. If you have credits with another provider, you can immediately send workloads to the other cloud by configuring a CloudBender deployment in that provider. Zero changes are needed to your pipelines and scripts, because they're already using the trainML interface. If your workloads are consistent enough that you're ready to invest in an physical server, you can add the server to CloudBender in a matter of minutes, and jobs will immediately begin routing to it. If you have more workloads than your server can handle, CloudBender will automatically burst the extra into your cloud account.
Additionally, systems attached to the CloudBender network can be configured to run jobs for other trainML customers while they are not being used. This way, customers without the capital for on-premise systems can still benefit from the lower cost of physical systems, and those with spare physical system capacity can reduce their cost of ownership even more by earning credits for their idle time.
Read about the configuring CloudBender and onboarding your resources.
Learn MoreFind out more about instance and storage billing and credits
Learn More